倍率理解
倍率设置是 MoleAPI 计费系统的核心配置。理解模型倍率、补全倍率、缓存倍率和分组倍率后,你就能看懂定价页上的倍率信息,也能根据日志快速核对一笔请求为什么会扣这么多。
倍率系统概述
MoleAPI 使用四类倍率来计算用户的配额消耗:
- 模型倍率(
ModelRatio):定义模型本身的基础计费倍数 - 补全倍率(
CompletionRatio):单独调整输出 token 的价格 - 缓存倍率(
CacheRatio):单独调整命中缓存的输入 token 价格 - 分组倍率(
GroupRatio):为不同分组设置差异化计费
配额与倍率的关系
在 MoleAPI 中,最终扣费会统一折算为配额点数。
1 美元 = 500,000 配额点数- 用户余额、消费记录本质上都是配额点数的增减
- 日志里常见的是美元形式的明细,后台最终会再换算成配额点数扣减
配额计算公式
按量计费模型(无缓存命中)
配额消耗 = (输入 token 数 + 输出 token 数 × 补全倍率) × 模型倍率 × 分组倍率按量计费模型(有缓存命中)
命中缓存时,不是把“缓存倍率”额外乘在总价上,而是只作用于那部分缓存输入 token。
配额消耗 = (普通输入 token 数 + 缓存 token 数 × 缓存倍率 + 输出 token 数 × 补全倍率) × 模型倍率 × 分组倍率按次计费模型(固定价格)
配额消耗 = 模型固定价格 × 分组倍率 × 500,000音频模型(特殊处理,new-api 内部自动处理)
配额消耗 = (文本输入 token + 文本输出 token × 补全倍率 + 音频输入 token × 音频倍率 + 音频输出 token × 音频倍率 × 音频补全倍率) × 模型倍率 × 分组倍率预消费与后消费机制
MoleAPI 采用预消费和后消费两阶段计费:
- 预消费:请求发出前按预估 token 先预扣
- 后消费:请求结束后按实际 token 重新计算
- 差额调整:实际费用与预扣费用不一致时自动补扣或退回
预消费配额 = 预估 token 数 × 模型倍率 × 分组倍率
实际配额 = 实际 token 数 × 模型倍率 × 分组倍率
配额调整 = 实际配额 - 预消费配额模型倍率设置
模型倍率定义了不同 AI 模型的基础计费倍数,系统会为常见模型预设默认值。
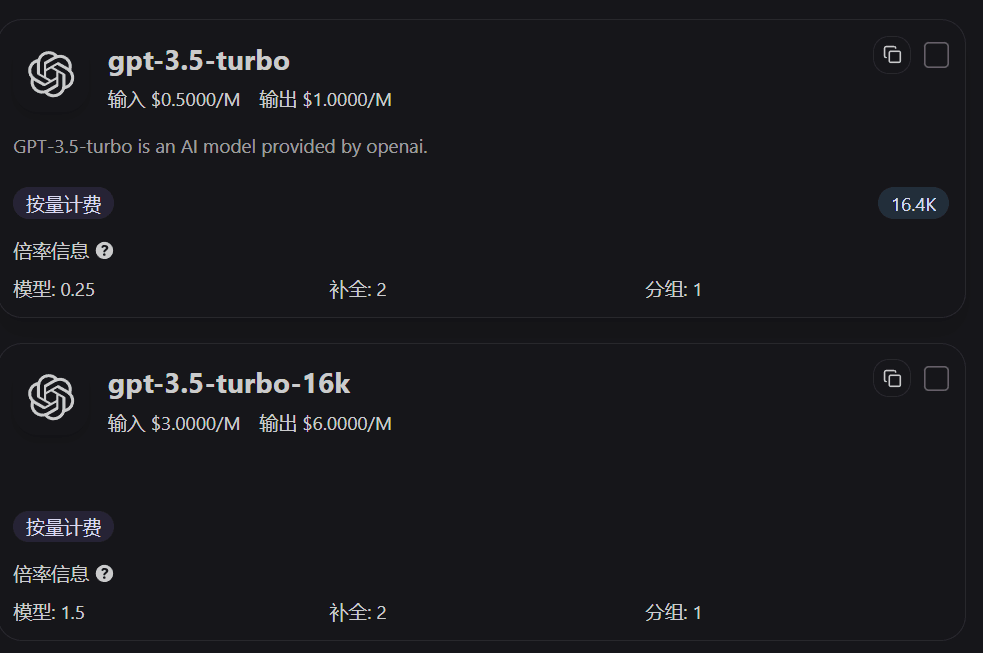
常见模型倍率示例
| 模型名称 | 模型倍率 | 补全倍率 | 官网价格(输入) | 官网价格(输出) |
|---|---|---|---|---|
| gpt-4o | 1.25 | 4 | $2.5/1M Tokens | $10/1M Tokens |
| gpt-3.5-turbo | 0.25 | 2 | $0.5/1M Tokens | $1.0/1M Tokens |
| gpt-4o-mini | 0.075 | 4 | $0.15/1M Tokens | $0.6/1M Tokens |
| o1 | 7.5 | 4 | $15/1M Tokens | $60/1M Tokens |
倍率含义可以这样理解:
- 模型倍率越高,整体基础成本越高
- 补全倍率越高,输出 token 越贵
- 缓存倍率越低,缓存命中时越省
- 分组倍率越低,最终给用户的实际扣费越低
补全倍率设置
补全倍率用于对输出 token 进行额外计费,主要是为了反映“输出比输入更贵”的现实成本差异。
默认补全倍率
| 模型类型 | 官网价格(输入) | 官网价格(输出) | 补全倍率 | 说明 |
|---|---|---|---|---|
| gpt-4o | $2.5/1M Tokens | $10/1M Tokens | 4 | 输出是输入的 4 倍 |
| gpt-3.5-turbo | $0.5/1M Tokens | $1.0/1M Tokens | 2 | 输出是输入的 2 倍 |
| gpt-image-1 | $5/1M Tokens | $40/1M Tokens | 8 | 输出是输入的 8 倍 |
| gpt-4o-mini | $0.15/1M Tokens | $0.6/1M Tokens | 4 | 输出是输入的 4 倍 |
| 其他模型 | 1 | 1 | 1 | 输入输出等价计费 |
在定价页怎么看倍率
定价页的模型卡片会直接展示模型倍率、补全倍率和分组倍率。先看这三个值,就能快速判断“同样一次调用,为什么这个模型比另一个模型更贵”。
缓存倍率设置
缓存倍率是很多人第一次看日志时最容易误解的地方。
缓存倍率到底作用在哪
它只作用于命中缓存的输入 token,不会作用于:
- 未命中缓存的普通输入 token
- 输出 token
- 整笔请求的总价
也就是说,一笔请求里如果同时出现普通输入和缓存输入,它们会分别按不同价格计算,然后再一起乘上分组倍率。
什么时候你会在日志里看到缓存倍率
当上游模型支持提示缓存,且这次请求实际命中了缓存时,日志里通常会额外看到:
缓存 Tokens缓存倍率缓存价格
如果没有命中缓存,这几行就不会参与最终费用计算。
分组倍率设置
分组倍率允许为不同渠道分组设置差异化价格,实现例如默认组、折扣组、转发组、试用组等不同策略。
分组倍率配置
{
"default": 1,
"discount": 0.8,
"relay": 0.3,
"trial": 0.1
}Q:分组倍率如何生效?
A:分组倍率会在最后阶段统一作用到整笔请求上。可以把它理解为“最终面向用户的价格系数”。
Q:补全倍率的作用是什么?
A:补全倍率主要用来平衡输入和输出 token 的成本差异。很多模型的输出价格明显高于输入价格,所以日志里会把输出 token 单独按补全倍率折算。
Q:缓存倍率的作用是什么?
A:缓存倍率只影响缓存命中的输入 token。缓存倍率越低,命中缓存时这部分 token 的实际成本越低。
QA 计算实例
下面的例子不是抽象公式,而是直接按日志中的字段一步一步核算。
Q1:一笔带缓存的请求,为什么日志里会多出“缓存价格”这一行?
因为这次请求命中了缓存,系统把输入 token 拆成了两部分:
- 普通输入 token:按输入价格计算
- 缓存命中 token:按输入价格再乘缓存倍率计算
下面这张日志就能看到 缓存 Tokens 3072、缓存倍率 1 和 缓存价格:

根据日志中的数字,计算过程是:
输入费用 = 62 / 1M × $0.250000 = $0.0000155
缓存费用 = 3072 / 1M × $0.250000 = $0.000768
输出费用 = 1193 / 1M × $2.000000 = $0.002386
最终费用 = (输入费用 + 缓存费用 + 输出费用) × 分组倍率 1
= $0.0031695
≈ $0.003170如果换算成配额点数,大约是:
$0.003170 × 500,000 ≈ 1,585 配额点数Q2:没有缓存命中时,费用应该怎么核对?
没有缓存命中时,就只需要看普通输入和输出两部分,不会出现缓存价格。

日志里的字段对应计算如下:
输入费用 = 827 / 1M × $0.250000 = $0.00020675
输出费用 = 338 / 1M × $2.000000 = $0.000676
最终费用 = (输入费用 + 输出费用) × 分组倍率 1
= $0.00088275
≈ $0.000883换算成配额点数,大约是:
$0.000883 × 500,000 ≈ 441 配额点数Q3:缓存倍率和分组倍率同时存在时,应该先算哪个?
先分别算出输入、缓存、输出三部分的费用,再统一乘分组倍率。下面这张日志同时包含了:
- 模型倍率
1.25 - 缓存倍率
0.1 - 输出倍率
6 - 分组倍率
0.3

按日志中的价格明细核算:
普通输入费用 = 357360 / 1M × $2.500000 = $0.893400
缓存费用 = 30208 / 1M × ($2.500000 × 0.1) = $0.007552
输出费用 = 100 / 1M × $15.000000 = $0.001500
最终费用 = (普通输入费用 + 缓存费用 + 输出费用) × 分组倍率 0.3
= ($0.893400 + $0.007552 + $0.001500) × 0.3
= $0.2707356
≈ $0.270736这也正是为什么日志里会单独显示:
- 输入价格:
$2.500000 / 1M tokens - 输出价格:
$15.000000 / 1M tokens - 缓存价格:
$2.500000 × 0.1 = $0.250000 / 1M tokens
Q4:怎么从倍率反推一张模型卡片大概贵不贵?
最简单的顺序是:
- 先看模型倍率,判断这个模型的基础成本高不高
- 再看补全倍率,判断输出内容会不会明显更贵
- 如果模型支持缓存,再看缓存倍率,判断缓存命中后能省多少
- 最后看分组倍率,判断你当前分组下的实际面向用户价格
如果你在定价页看到某个模型:
- 模型倍率高
- 补全倍率高
- 分组倍率也高
那它在长输出场景下通常会明显更贵;反过来,如果缓存倍率低且缓存命中率高,这类请求的实际费用就会下降得更明显。
有关更多计费规则,请查看常见问题
这篇文档对您有帮助吗?
最后更新于